Problem Description
Training robust Artificial Intelligence (AI) models requires vast amounts of high-quality, labelled data. However, collecting and manually annotating real-world data is a primary bottleneck; it is expensive, time-consuming, and often fails to capture rare but critical edge cases. Synthetic data generation offers a powerful solution, providing the ability to create virtually unlimited, perfectly labelled datasets. This approach allows for full control over object variation, lighting, and scene composition.
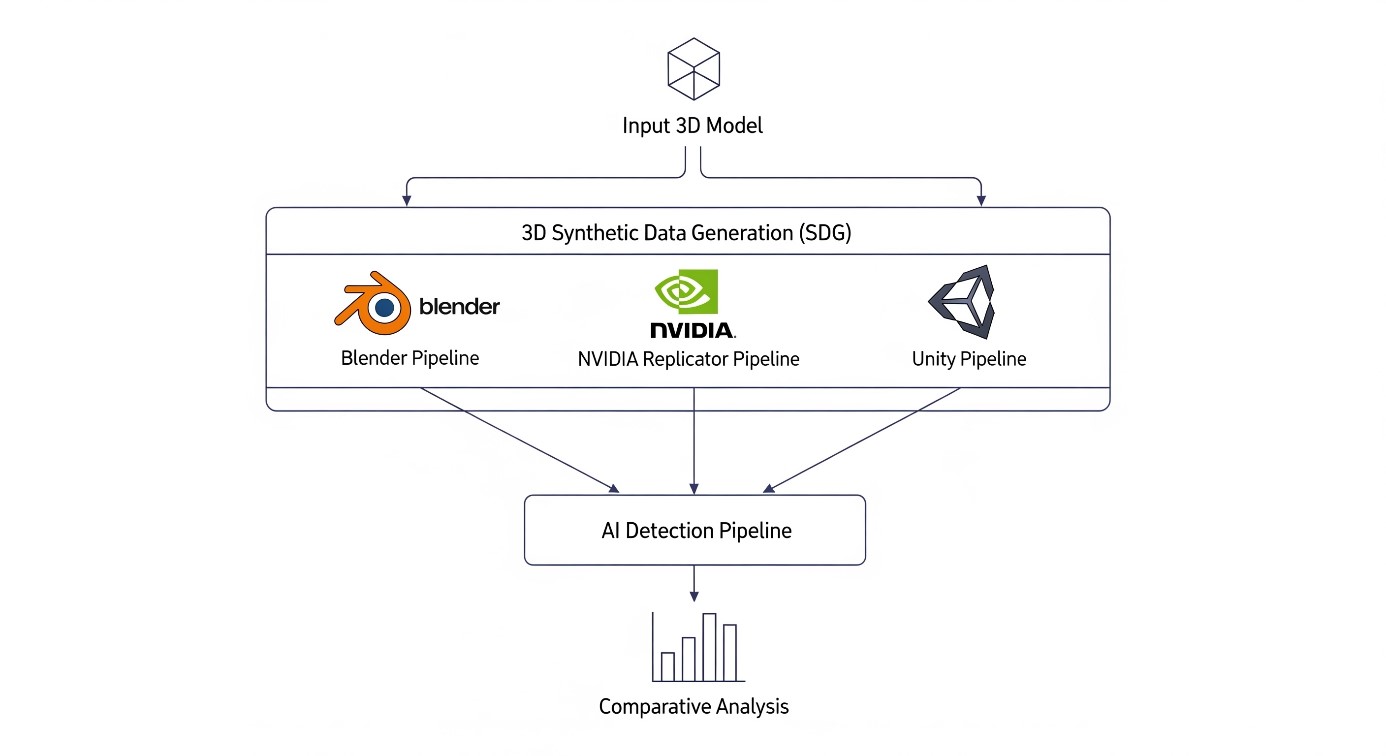
The choice of generation tool has significant practical implications. This project addresses a crucial question for modern AI developers: What are the trade-offs between using a flexible open-source 3D suite (Blender), a specialized data synthesis platform (NVIDIA Replicator), and a powerful real-time game engine (Unity)? This study will provide a clear, evidence-based framework for this decision by systematically comparing the pipelines on model accuracy, development effort, and generation speed, highlighting the fundamental differences between offline photorealistic rendering and real-time simulation.
Project Definition
This project is structured as a development and comparative study. Students will work in teams to design, build, and evaluate data generation pipelines for a custom object detection task. The core project will involve an in-depth comparison of two pipelines: one scripted using the Python API for Blender, and the other using the NVIDIA framework. Both will implement advanced domain randomization techniques (randomizing pose, lighting, textures, and camera angles).
It is also possible to extend the project implementing a third data generation pipeline using the Unity Engine and its Perception Toolkit.
- Literature review.
- Asset Preparation: Standardizing the provided 3D models
- Pipeline Development: Writing the automated data generation and annotation scripts.
- Model Training: Training a standardized object detection model on the datasets.
- Evaluation & Analysis: Testing the models against real-world dataset and conducting a comparative analysis.
The final deliverables will include a fully documented code repository for pipelines, the generated datasets, the trained model weights and a comprehensive final report detailing the methodology and findings.
Learning Outcome
Upon successful completion of this project, students will have acquired a deep, practical understanding of the entire data - centric AI workflow. They will be proficient in:
- Synthetic Data Generation
- Advanced Python Scripting.
- Deep Learning for Computer Vision
- Experimental Design & Analysis
- Interdisciplinary Teamwork
Participation Requirements
Practical experience in Python programming is mandatory. Basic understanding of machine learning concepts, 3D software (like Blender or unity) and Git. A strong willingness to make yourself familiar with new software platforms and a proactive approach to problem-solving.
External Partner
Innovation Hub Bergisches Rheinland